Sugar
Sugar
We propose Sugar: Structure-induced approach to unify generative and discriminative paradigms, leveraging discriminative training to acquire the two abilities above while harnessing the potential of generative training in complex discriminative tasks like image-text interleaved retrieval and fine-grained retrieval.

(a) Dynamic Sequence Alignment. Semantically matched slices are connected with a blue dashed line. The arrows indicate the direction of the ordered temporal alignment path. With these alignments, we can obtain the similarity between two interleaved inputs for training.
(b) Sugar Framework. Sugar supports both multi-modal generation and retrieval simultaneously.
Specifically, we explicitly impose the semantic relationships between different input samples as an induced structural constraint on the hidden state of MLLMs. We consider the interleaved image-text sequence as the general format of input samples, and then formulate the relationship between any two samples as a dynamic sequence alignment problem within the Dynamic Time Warping framework. In this way, we can explicitly modulate the hidden states of the MLLM by leveraging the semantic relationships between interleaved input sequences, thereby encouraging the MLLM to fully capture the global semantics of the multi-modal inputs.
To further enhance the ability to differentiate fine-grained semantics, we integrate a novel kernel into the Dynamic Time Warping framework. Leveraging the strengths of various discriminative pre-trained models, it performs dynamic sequence alignment for diverse embeddings tailored to specific contexts, thus addressing the inherent limitations in fully utilizing input semantics.

Our structure-induced generative and discriminative training joint training strategy.
Sugar is capable of producing compelling results on various vision-language tasks and has demonstrated some emergent abilities.
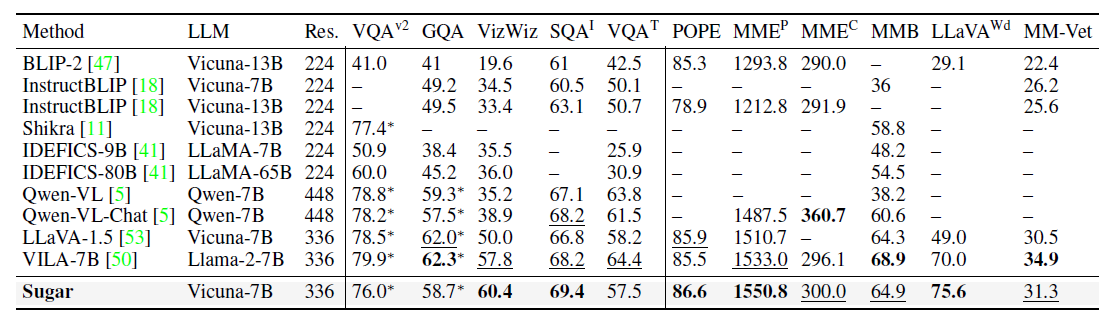
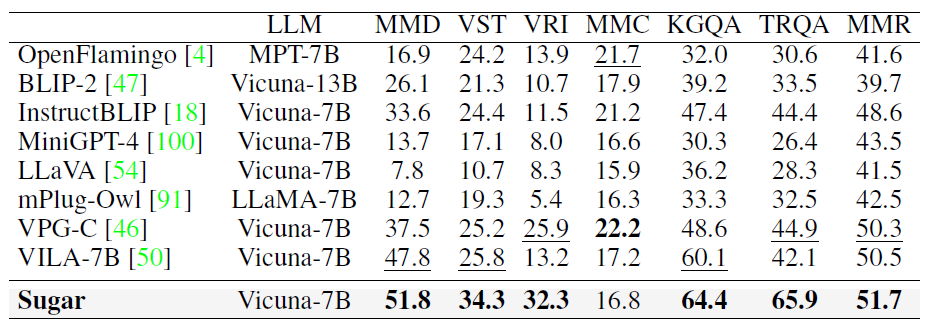
Comparison with state-of-the-art methods on 11 visual-language benchmarks
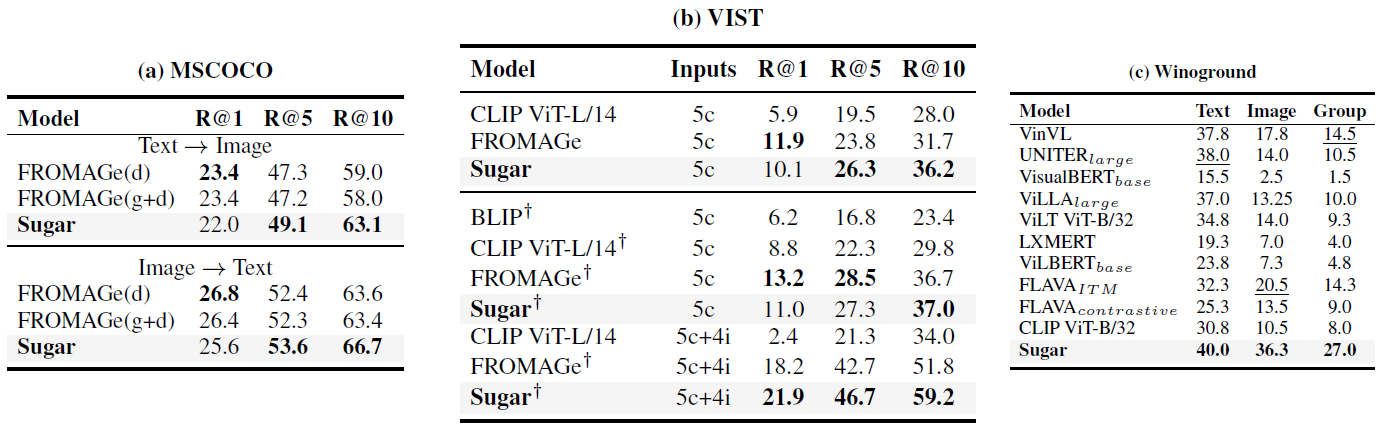
Retrieval results compared with previous models, reported by Recall@k for (a)(b) and Accuracy (%) for (c). (a) MSCOCO for image-text retrieval: FROMAGe(d) indicates the FROMAGe model pre-trained only with discriminative loss, and FROMAGe(g+d) indicates joint training with both discriminative and generative losses. (b) VIST for interleaved retrieval: † indicates retrieval over images not previously seen in the story sequence. "5c+4i" is shorthand for 5 captions and 4 images, and "5c" is shorthand for 5 captions. (c) Winoground for fine-grained retrieval.
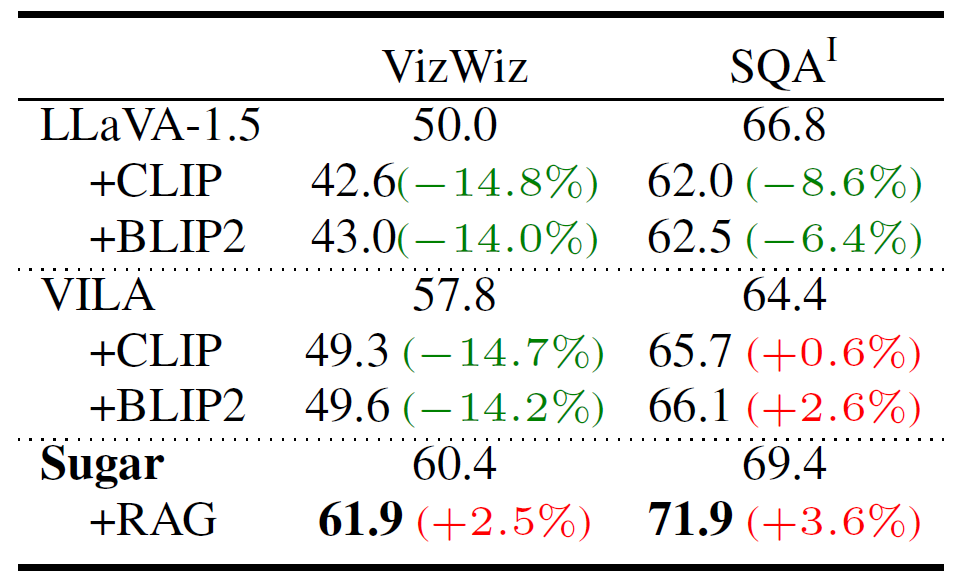
Retrieval-Augmented Generation.
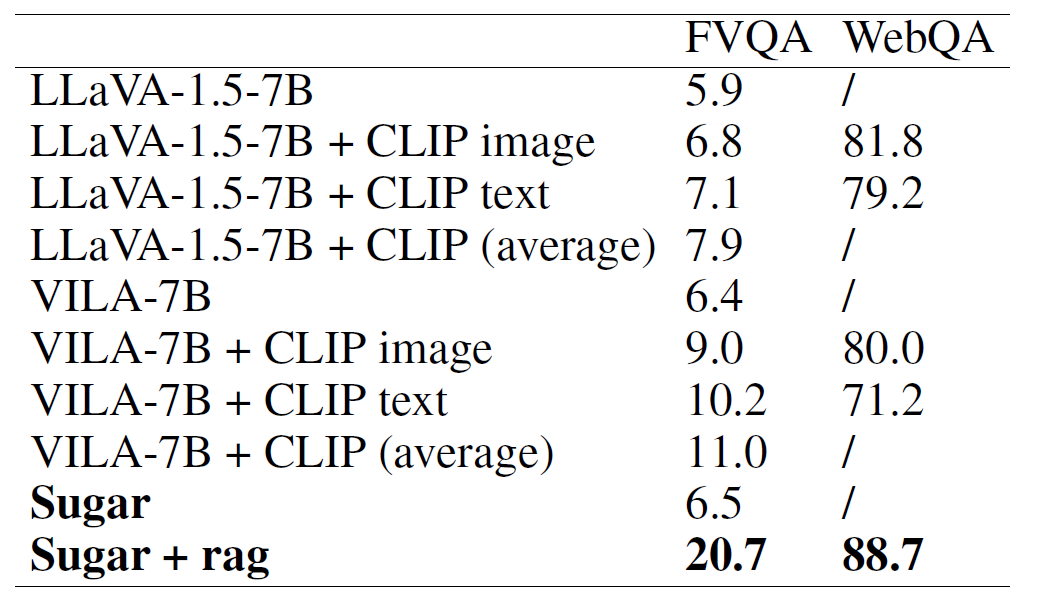
Comparison between the independent generator + retriever and Sugar on knowledge-based VQA. ’/’ indicates not applicable.
Below are selected examples for various image-text tasks. The pink background indicates retrieval results, while the blue background indicates generated results.

Sensitivity with Detailed Semantics

World Knowledge

Fine-grained Image Discrimination

Multimodal Concept Composition

Retrieval and Dialog
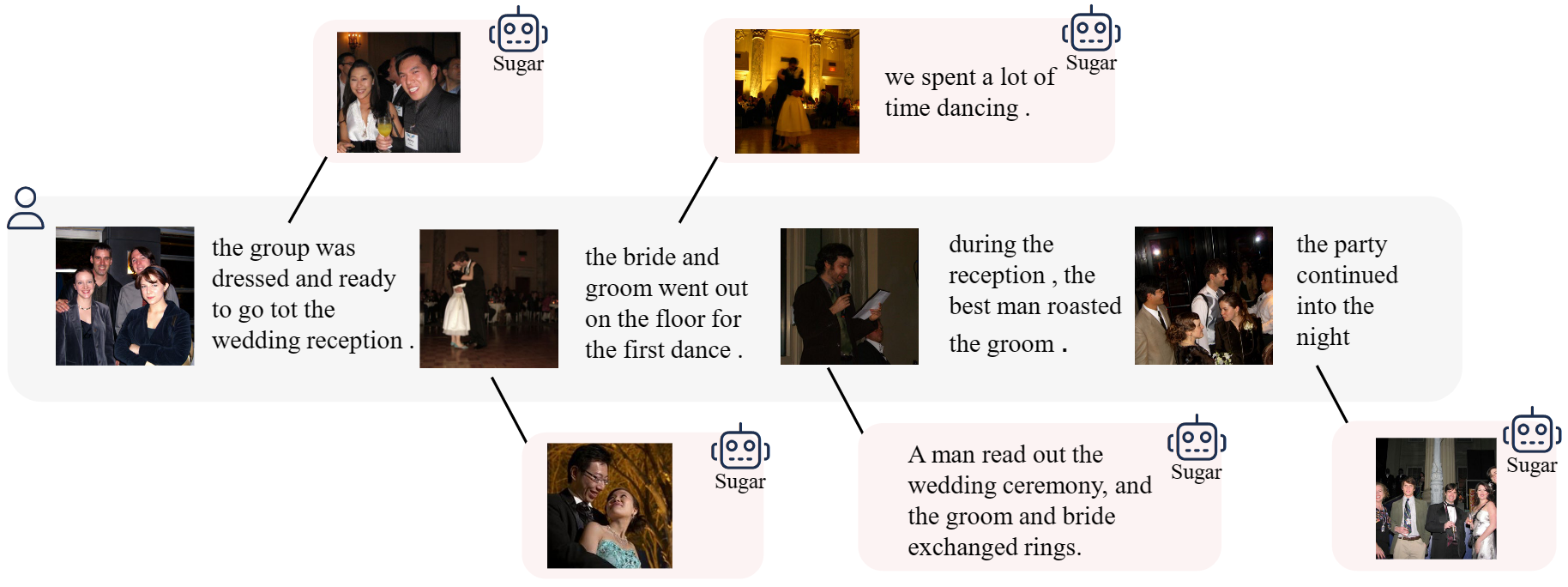
Retrieval at Different Place
@article{chow2024unified,
title={Unified Generative and Discriminative Training for Multi-modal Large Language Models},
author={Chow, Wei and Li, Juncheng and Yu, Qifan and Pan, Kaihang and Fei, Hao and Ge, Zhiqi and Yang, Shuai and Tang, Siliang and Zhang, Hanwang and Sun, Qianru},
journal={arXiv preprint arXiv:2411.00304},
year={2024}
}